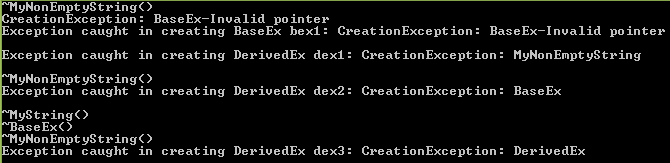
"Write a function which gives the length of the largest palindrome found within a string."
2. Solution
This solution provides algorithm complexity of O(N) and space complexity of O(1). The idea is to go through the string and compare the current character with its previous one and the one before the last. If they are equal, then set the flag that a palindrome is to start and set the a temporary index points to either the previous one or the one before the last. Then increment current index and decrement the temporary index if the characters that they are pointing to are equal. If not, then clear the flag and increment the current pointer only until a new palindrome is found or reaches the end of the string.
Pseudo-code
1. If the string is empty, then return -1.
2. If the string has only one character, then return 1.
4. If the string has two characters,
return 2, if two characters are equal,
return 1, if they are not
5. Assign tempIndex = 0; curIndex = 1; foundPalindrome = false and palindromeLength = 1
6. If str[curIndex] is equal to str[curIndex - 1], then set tempIndex = curIndex -1 and foundPalindrome = true. Increment curIndex until str[curIndex] is equal to str[tempIndex] and str[curIndex + 1] is not euqal to str[tempIndex], Go to Step 8,
7. If str[curIndex] is equal to str[curInex - 2] (only if curIndex - 2 is valid index), then set tempIndex = curIndex - 2 and foundPalindrome = true.
8. Increment curIndex anyway, If str[curIndex] is euqal to str[tempIndex - 1] (only if tempIndex -1 is a valid Index), decrement tempIndex.
9. Repeat Step 8 until
9. 1 curIndex reaches the end of str: then save the result if (curIndex - tempIndex) > palindromeLength and return.
9.2 tempIndex - 1 reaches beyond the start of str or str[curIndex] != str[tempIndex - 1]: then clear foundPalindrome and save the result if (curIndex - tempIndex) > palindromeLength. Then go to Step 6.
Corner cases:
Empty string: no palindrome found
One character string: regarded as a palindrome with only one character
Therefore any non-empty string will return a length >= 1. For instance a string is composed of all different characters will return 1.
Explanation on Step 6:
Initially I was not doing this - "Increment curIndex until str[curIndex] is equal to str[tempIndex] and str[curIndex + 1] is not euqal to str[tempIndex],", but simply go to Step 8 directly.
It turns out that not doing this hides a bug when working on a string like "AAAAAAAAA". It returns 8 rather than 9. Because Step 6 is done before Step 7.
Complexity analysis:
4 temporary variables are used, therefore the space complexity is O(1). And the largest palindrome can be found with one traversing the string, hence the algorithm complexity is O(N).
3. C++ Implementation
// Implementation
// This implementation returns more than just the length of the largest palindrome.
// It returns the start position and the length of the first largest palindrome, if it has
// more than one candidates.
// ********************************************************************************
#include <string>
struct PalindromeInString
{
int pos; // start position in string
int len; // length of palindrome
};
PalindromeInString FindLargestPalindromeInString(const std::string& str)
{
if (str.empty()) {
return PalindromeInString{ -1, -1 };
}
if (str.length() == 1) {
return PalindromeInString{ 0, 1 };
}
if (str.length() == 2) {
if (str[0] == str[1]) {
return PalindromeInString{ 0, 2 };
}
else {
return PalindromeInString{ 0, 1 };
}
}
PalindromeInString result = { 0, 1 };
bool found = false;
size_t tempIndex;
size_t curIndex;
for (tempIndex = 0, curIndex = 1; curIndex < str.length(); ++curIndex) {
if (!found) {
if (str[curIndex] == str[curIndex - 1]) {
// Step 6
found = true;
tempIndex = curIndex - 1;
while ((curIndex + 1) < str.length()) {
if (str[curIndex + 1] != str[tempIndex]) {
break;
}
else {
++curIndex;
}
}
}
else if (curIndex > 1 && str[curIndex] == str[curIndex - 2]) {
// Step 7
found = true;
tempIndex = curIndex - 2;
}
else {
continue;
}
}
else {
// Step 9
if (tempIndex > 0 && str[curIndex] == str[tempIndex - 1]) {
--tempIndex;
}
else {
found = false;
// save the palindrome with max length found so far
if (result.len < (curIndex - tempIndex)) {
result = { tempIndex, curIndex - tempIndex };
}
}
}
}
if (found && result.len < (curIndex - tempIndex)) {
result = { tempIndex, curIndex - tempIndex };
}
return result;
}
// ********************************************************************************
// Test
// ********************************************************************************
#include <cassert>
void TestCornerCases()
{
PalindromeInString result = FindLargestPalindromeInString("");
assert(result.pos == -1 && result.len == -1);
result = FindLargestPalindromeInString("A");
assert(result.pos == 0 && result.len == 1);
result = FindLargestPalindromeInString("AA");
assert(result.pos == 0 && result.len == 2);
result = FindLargestPalindromeInString("AB");
assert(result.pos == 0 && result.len == 1);
}
void TestCase1()
{
PalindromeInString result = FindLargestPalindromeInString("123ABCDEFGGFEDCBA123");
assert(result.pos == 3 && result.len == 14);
result = FindLargestPalindromeInString("123ABCDEFGFEDCBA123");
assert(result.pos == 3 && result.len == 13);
}
void TestCase2()
{
PalindromeInString result = FindLargestPalindromeInString("123XYZZYXABCDEFGGFEDCBA123");
assert(result.pos == 9 && result.len == 14);
result = FindLargestPalindromeInString("123XYZYXABCDEFGFEDCBA123");
assert(result.pos == 8 && result.len == 13);
}
void TestCase3()
{
PalindromeInString result = FindLargestPalindromeInString("123AAAAAAAAAAAA123");
assert(result.pos == 3 && result.len == 12);
result = FindLargestPalindromeInString("123AAAAAAAAAAA123");
assert(result.pos == 3 && result.len == 11);
}
void TestCase4()
{
PalindromeInString result = FindLargestPalindromeInString("AAA");
assert(result.pos == 0 && result.len == 3);
result = FindLargestPalindromeInString("AAAAAAAAAA");
assert(result.pos == 0 && result.len == 10);
result = FindLargestPalindromeInString("AAAAAAAAAAA");
assert(result.pos == 0 && result.len == 11);
}
void TestCase5()
{
PalindromeInString result = FindLargestPalindromeInString("ABACCDCCAEFBFEACCD");
assert(result.pos == 5 && result.len == 13);
result = FindLargestPalindromeInString("abac");
}
// ********************************************************************************